
Google Cloud Platform has excellent toolset to operationalize and productionize machine learning models.
Vertex AI is the key MLOps product while Google Kubernetes Engine is valid alternative for custom workflows.
ML operationalization vs deployment
Here are three levels of ML process maturity:
- Build and deploy manually
- Automate training (operationalization)
- Automate training, validation and serving (deployment)
The term operationalization is often misunderstood. It simply means automating the model training. Here are typical steps
- Write tunable training script
- Package to container
- Run in a service like Vertex AI Jobs
Containers and Docker
Virtualization: Multiple OS kernels share the same hardware.
Containerization: Multiple applications share the kernel. The container runtime sits between the apps and the kernel. Containers have individual dependencies.
Docker is a containerization tool. It has these components:
| Docker component | Use case |
|---|---|
| Docker Engine | Interface for user interaction. |
| containerd | Docker runtime also known as Docker daemon. |
| runc | OCI (Open Container Initiative) compliant runtime for containers. |
Each command in Dockerfile stacks up a new layer. The bottom layers are called as base image layers. The topmost layer runs the application and is called as container layer. Only the top layer can be modified.
The concept of union file system enables sharing the base images while having individual dependencies between containers.
Kubernetes features
- Stateful (eg database) and stateless applications
- Autoscaling
- Resource limites
- Extensibility
- Portability
Here you can read my Kubernetes tutorial.
Kubernetes concepts
Kubernetes objects are persistent entities representing the state of the cluster. The objects have these properties:
- Object spec: Defined by developer
- Object status: Given by Kubernetes
Each object has a type. Pods are the basic building blocks. They are the smallest deployable Kubernetes objects (container would be wrong answer).
Pod encapsulates one or more containers. They are closely related and share common resources including networking and storage. Each Pod has an IP address.
A deployment describes the Kubernetes state in a YAML file. Kubernetes then creates a deployment object from the definition while the controller constantly monitors and applies the changes.
A deployment can configure a ReplicaSet controller to create and maintain the defined pods.
Kubernetes components
A Kubernetes cluster has the master machine and nodes. The master is called Control Plane. The pods run on nodes.
The Control Plane run multiple services. The kube-apiserver is the main communication channel between them.
| Kubernetes component | Use case |
|---|---|
| cubectl | User interaction |
| etcd | Kubernetes meta data database |
| kube-scheduler | Decides in which node a pod should be ran |
| kuber-controller-manager | Exceutes the changes to nodes |
| kuber-cloud-manager | Provision resources on cloud providers |
Each node has a Kubelet and Kube-proxy. Kubelet is the interface between Control Plane and node. Kube-proxy is responsible of network connectivity within cluster.
Kubernetes deployment
Here are different types of deployments for ReplicaSets. This is defined in the strategy attribute of the spec.
| Kubernetes deployment strategy | How it works |
|---|---|
| Rolling updates | Replace a few of pods at the time. Define min and max tresholds for total number of pods. |
| Blue-Green deployments | The new deployment replaces the old one at once |
| Canary deployments | The new deployment runs in parallel with the old one in production |
Kubernetes jobs
Jobs can be scheduled in Kubernetes. It is possible to define parallelism and number of tasks to complete. Jobs have some similarities to deployments in a sense that they are defined in YAML spec, an object is created and a controller manages the execution.
When using work queues, set parallelism but do not define completions empty.
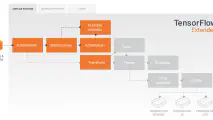
Kubeflow and Kubeflow Pipelines
Kubeflow is a Kubernetes framework for developing ML workloads.
Kubeflow Pipelines is a Kubeflow service to orchestrate and automate modular ML pipelines.
The Kubeflow Pipelines can be packaged and shared as ZIP files.
Pipeline is the top component. The main Kubernetes package for pipelines and components is kfp.dsl. DSL = Domain Specific Language. It has wrapper functions @dsl.component and @dsl.pipeline.
Component specifications can also be downloaded directly from GitHub within the code.
A pipeline consists of components that correspond to a container. Lightweight Python functions are allowed to be run without a full container.
Where to do preprocessing in Google Cloud?
Data preprocessing for ML pipelines can be performed in:
| Google Cloud service | When to do preprocessing |
|---|---|
| BigQuery | Batch data. Not for full-pass transformations. |
| Dataflow | For expensive processing. |
| Tensorflow | Instance (row) level transformations. Full pass with tf.Transform. |
Online vs batch predictions
All predictions can be computed beforehand to a database if the number of predictions is low.
If the number of possible predictions is high or even unknown, online prediction is the way to go. In practice it would mean calling and API that computes the prediction on the fly with the given ML model.
Google also talks about static vs dynamic training in their materials. Even though the term is training I felt that the lecture confused training and prediction to each other. I would think that regardless of the domain, all models require small adjustements every now and then which makes the training always dynamic.
Features in MLOps
Data leakage means that some features used in the training are actually not available on prediction time.
Ablation analysis is a study where one feature at the time is left out from the model training. This should reveal information about the significance about the feature.
Legacy features have became redundant due to improved features.
Bundled features are important together but not individually.
Skew and drift for ML model monitoring
There are two approaches to monitor for data quality:
| Data quality issue | Description |
|---|---|
| Skew | Detect if training and serving data are generated differently. |
| Drift | Features, label or both change in serving over time. Training data is not involved. |
Both skew and drift calculate statistical distributions for each feature to detect significant changes. They are essentially using same methods such as Jensen-Shannon divergence for numerical features and L-infinity for categoricals.
It is somewhat obvious that drift is monitored continuously. Skew can be detected right after the deployment, but also later at any moment. For example a sudden change in input data would cause skew.
For complex situation feature attributions can be used for drift and skew detection.
Different kinds of drifts
Drift can occur due to many reasons:
| Drif type | Explanation |
|---|---|
| Data drift | Input data distribution changes. Other common names for this are feature drift, population drift and covariate shift. |
| Concept drift | The relationship between input and output changes. |
| Label drift | Output variable distribution changes. |
| Prediction drift | Model works well, but for example one label receives much more prediction than before. The business might not have prepared for the scenario. |
| Model dirft | Combination of data drift and concept drift. When problems occur, the solution is to re-label and re-train. |
Feeback loop in machine learning
Feedback loop is stronger if the predicted outcome has strong impact to the next version of the model.
Physical phenomena and static datasets do not have feedback loops. Models that rely on previous behavior have strong feedback loops.
| An ML model use case | Is it feedback loop? |
|---|---|
| Traffic forecasting | Yes |
| Book recommendations | Yes |
| House price prediction | No |
| Image recognition from stock photos | No |
Performance tuning for ML training
| ML training constraint | Cause | Action |
|---|---|---|
| I/O | Large input dataset | Parallelize reading |
| CPU | Expensive computation | Use GPU or TPU |
| Memory | Complex model | Add memory, reduce batch size |
Distributed training architectures
Distributed training is performed simultaneously on multiple machines. In this context machine is a synonym with worker, device and accelerator.
Synchronous data parallelism
- Calculate gradients as mini-batch per device
- Communicate gradients directly to others
- Calcualte eg the average of gradient in so called “AllReduce”
Suitable for dense models, stores the whole model on each step. Works best for multiple executors on a single host.
Asynchronous data parallelism
- Calculate gradients as mini-batch per device
- Communicate gradient to a parameter server
- Calcualte eg the average of gradient in so called “AllReduce”
Asynchronous has better ability to scale but can get out of sync. Better option for unreliable or low power workers. Better for large, sparse models as only the parameters are saved.
Model parellelism
Different parts (layers) of the model are split to different GPUs.
Hybrid ML models
Sometimes working fully in cloud is not possible.
Those cases might be:
- On-premise
- Multi cloud
- Edge
In this case Kubeflow is a good option.
Federated learning
An ML model training paradigm where the main model is updated on multiple edge devices without sharing the data.
This works so that each device first gets the base model. They then update the model locally and send only the updated model weights to cloud. The main model is then updated.
This workflow is more secure than traditional methods due to less data exchange.
TPU - Tensor Processing Units
Google provides TPUs aside of traditional CPU and GPU computation.
TPUs are suitable for large matrices that are trained from weeks to months. They are not recommended for high precision arithmetic.
TPUs use bfloat16
data type
for matrix operations.
What MLOps guide books do not teach you?
In reality the problems are complex.
There are existing code bases, multiple teams involved and budgeting questions.
It may take serveral attempts and months to years of organizational policy and framing the problem before all puzzle pieces are in ML Engineers hand.
Write a new comment
The name will be visible. Email will not be published. More about privacy.